Preprint Introduces Replay Framework for LLM Model Collapse Analysis
Here's what it means for you.
As language models evolve, understanding their training dynamics can influence how you leverage AI in your projects.
Why it matters
The integrity of generative AI outputs is crucial for industries relying on accurate and diverse language generation.
What happened (in 30 seconds)
- Research published: A new paper from the University of Copenhagen and Isara Labs details how replay of generated outputs can hinder language model training.
- Key findings: The study identifies conditions under which model collapse occurs, particularly in recursive training scenarios.
- Implications for AI: The results suggest that without proper data management, generative models may produce less reliable outputs.
The context you actually need
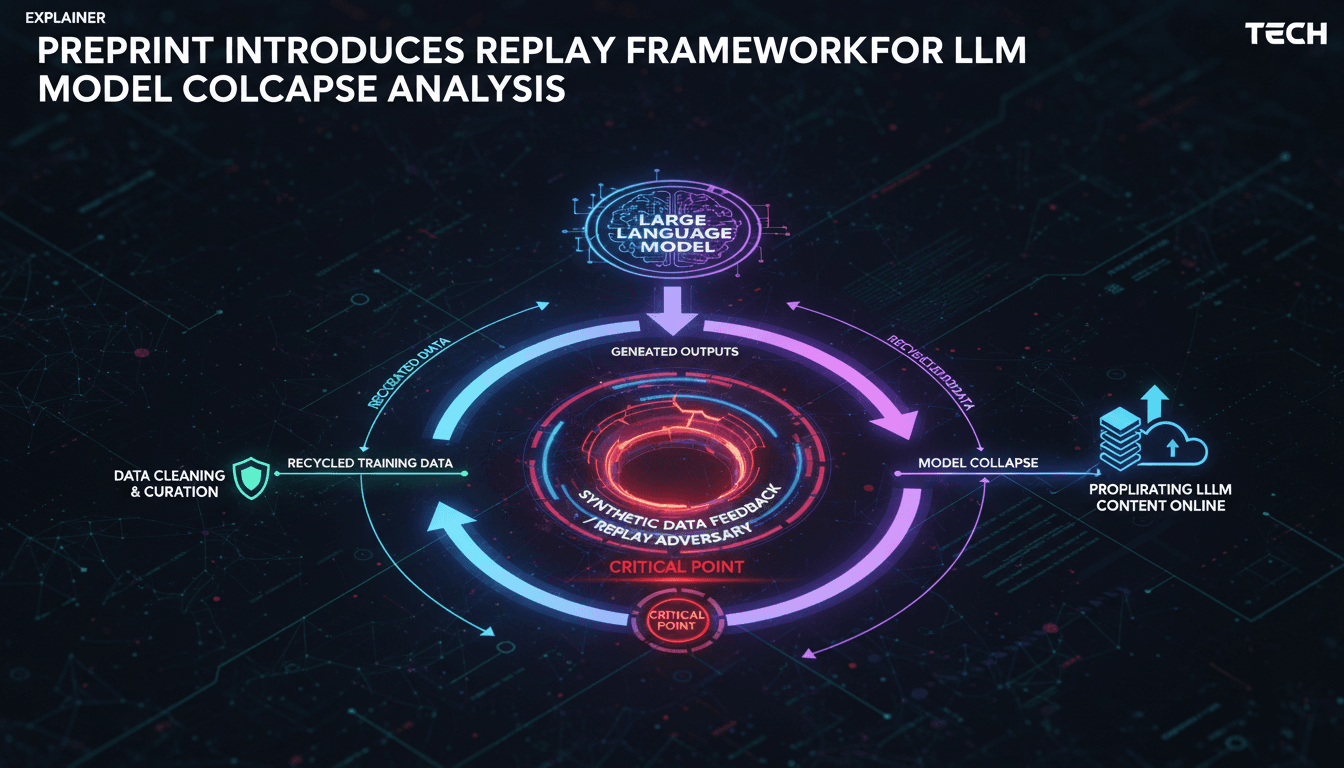
- Model collapse: This phenomenon refers to the degradation of performance in generative models due to contamination from their own synthetic outputs.
- Scaling laws: As language models grow, they require vast amounts of data, often leading to challenges in maintaining output quality.
- Replay adversary: The paper introduces a concept where past outputs are reintegrated into the training stream, complicating the learning process.
What's really happening
The recent research paper titled "Language Generation with Replay: A Learning-Theoretic View of Model Collapse" sheds light on the complex dynamics of language model training. At its core, the study investigates how the replay of previously generated outputs can lead to model collapse, a scenario where the performance of generative models deteriorates due to contamination from their own outputs. This is particularly relevant in the context of recursive training, where models are trained on datasets that may include their own generated text.
The authors, Giorgio Racca and Amartya Sanyal from the University of Copenhagen, alongside Michal Valko from Isara Labs, extend the existing framework of language generation by introducing a replay adversary. This adversary injects past generator outputs into the training stream, creating a feedback loop that can hinder the model's ability to learn effectively. The paper presents several key theorems that outline the conditions under which uniform generation remains robust to replay, while also highlighting the limitations faced by non-uniform generation.
One of the standout findings is encapsulated in Theorem 6.3, which indicates that proper generation in the limit fails for finite hypothesis classes of size four. This suggests that even with a limited set of potential outputs, the model struggles to maintain quality when replay is involved. The implications are significant for developers and researchers, as they underscore the necessity of implementing robust data cleaning and filtering heuristics to mitigate the risks associated with model collapse.
The study also emphasizes the importance of understanding the structural implications of these findings. As generative models become increasingly integrated into various applications, the potential for degraded performance due to replay dynamics poses a challenge. This is particularly critical for sectors that rely on high-quality language outputs, such as content creation, customer service automation, and even legal document generation. The research advocates for a more nuanced approach to training generative models, one that considers the interplay between generated outputs and the training data.
Who feels it first (and how)
- AI Developers: Need to adapt training methodologies to prevent model collapse.
- Content Creators: May experience reduced output quality if generative models are not properly managed.
- Businesses: Relying on AI-generated content could face challenges in maintaining brand voice and accuracy.
What to watch next
- Adoption of new training techniques: Watch for shifts in how language models are trained, particularly in the integration of data cleaning methods. This matters because improved training techniques can enhance output reliability.
- Industry response: Monitor how sectors reliant on generative AI adjust their strategies in response to these findings. This is crucial for understanding market trends and potential shifts in AI usage.
- Further research developments: Keep an eye on follow-up studies that may expand on or challenge these findings, as they could redefine best practices in AI training.
Model collapse can occur due to contamination from synthetic outputs.
Industries will need to implement stricter data management practices to maintain output quality.
The long-term effects of these findings on the evolution of generative AI technologies remain to be seen.
Frequently Asked Questions
- Why it matters?
- The integrity of generative AI outputs is crucial for industries relying on accurate and diverse language generation.
- What happened (in 30 seconds)?
- Research published: A new paper from the University of Copenhagen and Isara Labs details how replay of generated outputs can hinder language model training. Key findings: The study identifies conditions under which model collapse occurs, particularly in recursive training scenarios. Implications for AI: The results suggest that without proper data management, generative models may produce less reliable outputs.
- What's really happening?
- The recent research paper titled "Language Generation with Replay: A Learning-Theoretic View of Model Collapse" sheds light on the complex dynamics of language model training. At its core, the study investigates how the replay of previously generated outputs can lead to model collapse, a scenario where the performance of generative models deteriorates due to contamination from their own outputs. This is particularly relevant in the context of recursive training, where models are trained on datas
- Who feels it first (and how)?
- AI Developers: Need to adapt training methodologies to prevent model collapse. Content Creators: May experience reduced output quality if generative models are not properly managed. Businesses: Relying on AI-generated content could face challenges in maintaining brand voice and accuracy.
- What to watch next?
- Adoption of new training techniques: Watch for shifts in how language models are trained, particularly in the integration of data cleaning methods. This matters because improved training techniques can enhance output reliability. Industry response: Monitor how sectors reliant on generative AI adjust their strategies in response to these findings. This is crucial for understanding market trends and potential shifts in AI usage. Further research developments: Keep an eye on follow-up studies t
Machine Learning preprints from arXiv.
"Core ML theory and methods in daily preprints."
— A47 Editor
Language Generation with Replay: A Learning-Theoretic View of Model Collapse
Researchers have presented a learning-theoretic analysis of model collapse in large language models (LLMs), focusing on risks from replaying machine-generated content during training as data demands increase and synthetic text proliferates online.
Machine Learning preprints from arXiv.
"Core ML theory and methods in daily preprints."
— A47 Editor
Markovian Generation Chains in Large Language Models
A recent study introduces the concept of Markovian generation chains in large language models (LLMs), exploring how texts evolve through iterative processing without prior memory. The research highlights that outputs can either converge to a limited ...